最近在看一些资料,这里从 Core 架构入手,研究CPU 是如何读取执行一条指令的。从下面可以看到 Core 架构是很老的设计了:
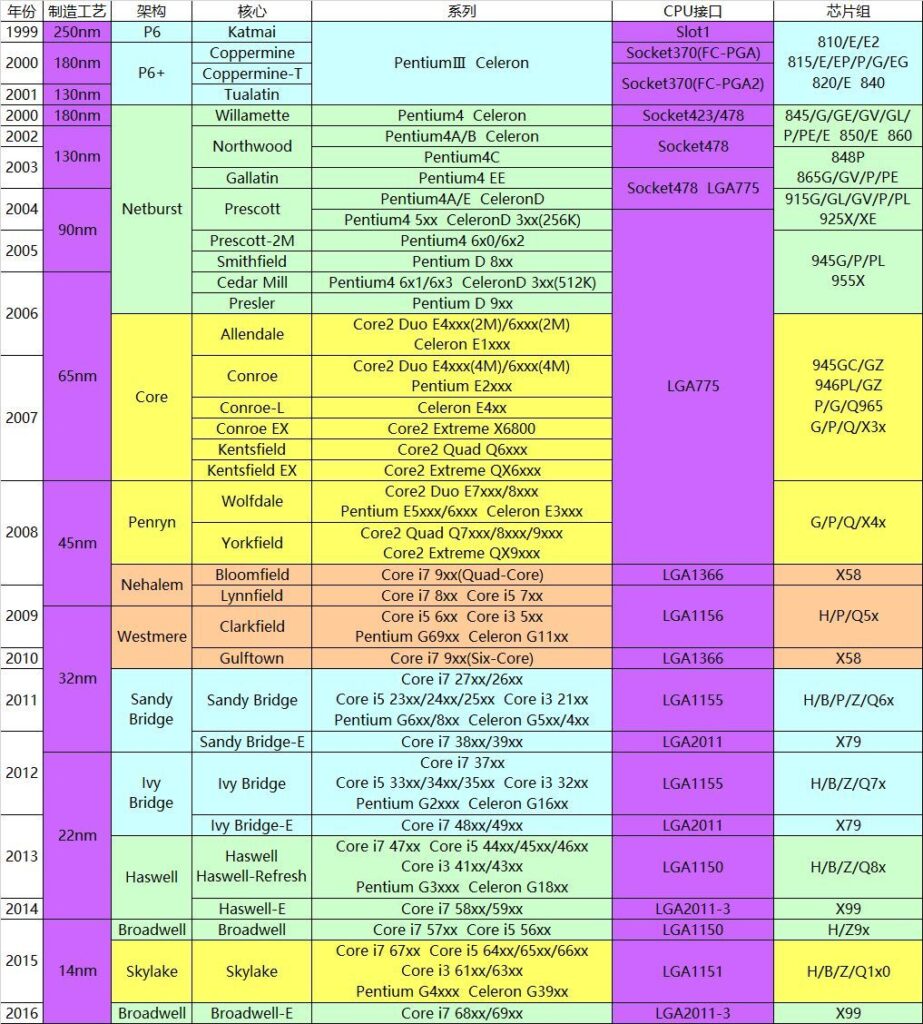
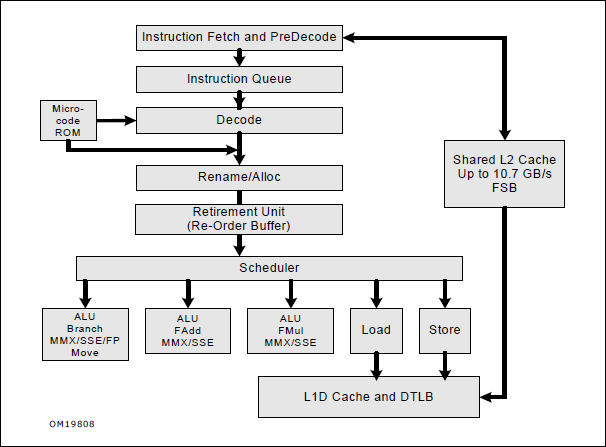
之所以选择 Core 来进行查看最主要的原因是整体流程非常清晰。
首先是“Instruction Fetch and PreDecode” 取得指令,“这个阶段指令预解码单元会接收到从instruction cache或者instruction prefetch buffer发出的16字节,并执行以下任务:”
- 解码出指令的长度
- 解码出指令的所有前缀
- 为指令打上标记(如“是分支 / is branch”)
之后放入 Instruction Queue 中。“Instruction Queue(IQ)最大的作用就是侦测并存储循环指令。IQ内提供了能存储小于18条指令的loop cache,如果loop stream detector(LSD)侦测到IQ内的指令为循环内的指令,则会把这些指令锁定下来,那么在循环期间就可以直接从IQ中获取指令到解码器,从而省去前面fetch以及predecode等工作。如此一来能很好地提高效率以及降低功耗。”
接下来是 Decode,这个阶段会将指令解释为微指令(μop),之前在 CISC 和 RISC 的介绍有提到过,Intel CPU 虽然是 CISC 架构,但是内部会将 CISC指令解释成为类似 RISC 的指令再进行执行。
Allocator/Renamer 是之前介绍过的寄存器重命名,Allocator 应该是为一些微指令(比如: load 和 store)创建 buffer。
Retirement (Reorder buffer, ROB) ,”主要用于记录μops的状态以及存储EU执行完成后返回的结果,然后按照in-order的顺序把执行结果写回寄存器,使得在用户层看来指令在以in-order的顺序执行,in-order写回的这一步被称为retirement。Core微处理器一共可以容纳96项μops。”
“Scheduler(RS)的目的是把μops分配到相应的execution port。为了实现这个目的,RS必须具备识别μop是否ready的能力。当μop的所有的源(source)都就位时则表明该μop为ready,可以让RS调度到execution unit执行。RS会根据Issue Port的可用情况以及已就绪μops的优先级来对μop进行调度。”【参考3】
接下来的指令会进入不同的 ALU 中进行执行,从图中可以看到这些ALU 相对独立,再在运行时可以并行进行,也正是因为这样的设计,保证了CPU的运行效率。
最终的运算结果放在L1D Cache 中。
上面的介绍大部分来自【参考2】,强烈推荐有兴趣的朋友阅读原文。最后再看一下最新的2个架构框图。分别是 Sandy Bridge 和 Icelake 的架构:
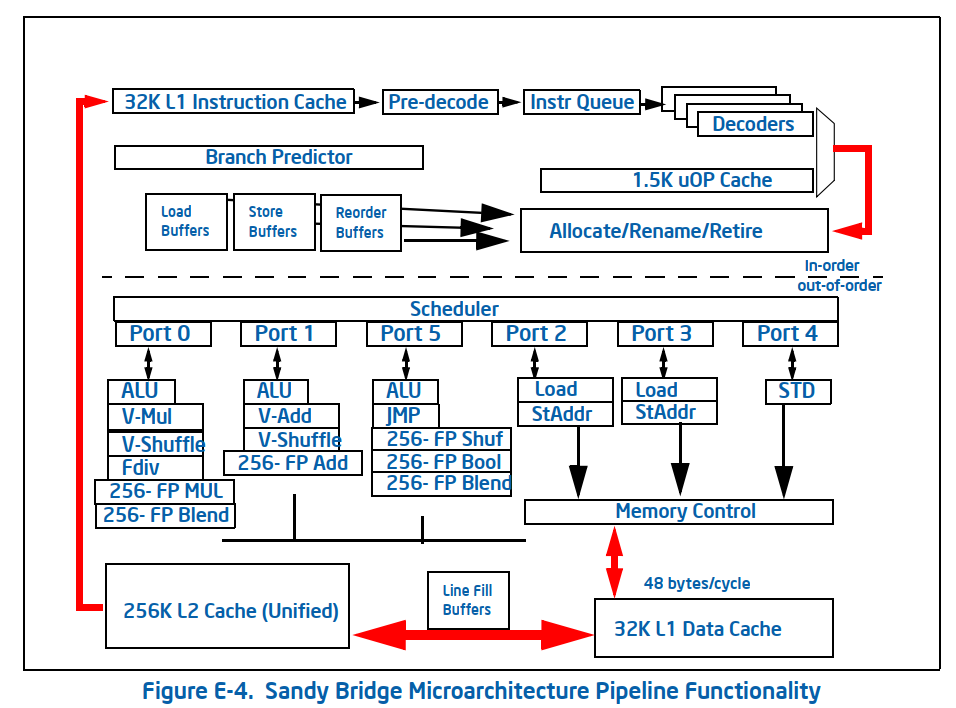
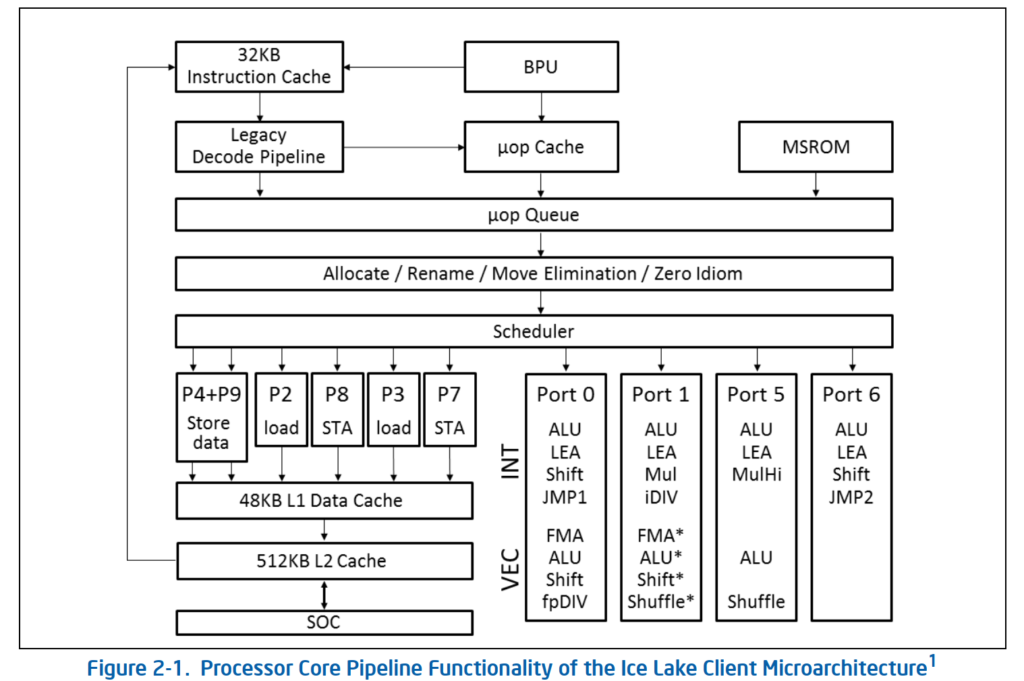
有了前面的知识理解这两个并不困难。
参考:
1.https://www.sohu.com/a/245702002_467792 Intel P6以来核心架构及对应型号、芯片组一览表
2.http://www.qdpma.com/systemarchitecture/IntelMicroArchitectureDiagrams.html
3.https://www.cnblogs.com/TaigaCon/p/7678394.html Intel Core Microarchitecture Pipeline
4.Intel® 64 and IA-32 Architectures Optimization Reference Manual