运行my目录中的bat文件生成linux.img,然后启动bochsrc.bxrc(2.4.1)可以看到运行的linux0.11啦,因为启动读取了硬盘的文件,所以hdc-0.11.img不能删除。
http://www.lab-z.com/wp-content/uploads/alinux/linux0112013.rar
运行my目录中的bat文件生成linux.img,然后启动bochsrc.bxrc(2.4.1)可以看到运行的linux0.11啦,因为启动读取了硬盘的文件,所以hdc-0.11.img不能删除。
http://www.lab-z.com/wp-content/uploads/alinux/linux0112013.rar
代码如下:
#include <stdio.h>
main()
{
printf("Hello, A !\n");
}
命名为 lab-z.com
gcc -o lab-z lab-z.c
./lab-z 即可运行
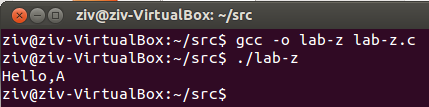
另外,还可以定义一个宏,输出当前运行到的位置(在Debug Firmware时会很有用)
#include <stdio.h>
#define dprint( args...) printf(args);printf("%s %d\n",__FILE__,__LINE__);
main()
{
printf("Hello,A\n");
dprint("Hello,B\n");
}
就像 http://www.lab-z.com/vc-%E4%B8%AD%E8%BE%93%E5%87%BA%E5%BD%93%E5%89%8D%E8%BF%90%E8%A1%8C%E7%9A%84%E6%96%87%E4%BB%B6%E5%92%8C%E6%89%80%E5%A4%84%E7%9A%84%E8%A1%8C%E6%95%B0%E4%BB%A5%E5%8F%8A%E6%89%80%E5%9C%A8%E5%87%BD/ 这篇文章提到的一样
参考:
1.http://ggmmchou.blog.163.com/blog/static/59333149201021512218461/ linux c 002 一个gcc的最简单例子
2.http://www.uml.org.cn/c++/200902104.asp C中的预编译宏定义
房屋在装修,因为是清包,事情很多,请了门口的上海黄腾装潢公司,更是纠缠不清,老婆动辄就被气哭。
唉,只能坚持下去了。
简单说“分词”就是指将一个句子拆分为一个个词语。调用的是“海量分词”的DLL库。
海量分词官方网站 http://www.hylanda.com/ (没看到有下载的地方)
试用装下载 http://www.onlinedown.net/soft/39759.htm
例子程序实际来自 https://code.google.com/p/jamessrc/source/checkout
这里我将上面的例子修改为动态调用。其中的 HLSSplit.dat 是DLL自带的分词库,在使用时需要通过 HLSplitInit 来指定这个库的路径。
主要代码例子如下
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls;
type
SHLSegWord=record
s_szWord:pchar ; //字符串
s_dwPOS:longint ; //词性标志
s_fWeight:single; //关键词权重,如果不是关键词,权重为0
end;
TForm1 = class(TForm)
Memo1: TMemo;
Button1: TButton;
Memo2: TMemo;
Label1: TLabel;
procedure Button1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
THLSplitInit = function (lpszDataFilePath:pchar):boolean;cdecl;
THLFreeSplit = function (): string;cdecl;
THLOpenSplit = function ():THANDLE;cdecl;
THLCloseSplit = function (hHandle:THANDLE ):boolean ;cdecl;
THLSplitWord = function (hHandle:tHANDLE ; b:LPCSTR ; iExtraCalcFlag:integer = 0):boolean;stdcall;
THLGetWordCnt = function (hHandle:tHANDLE ): integer;cdecl;
THLGetWordAt = function (hHandle:tHANDLE; iIndex:integer):Pointer ;cdecl;
var
Form1: TForm1;
const HL_CAL_OPT_KEYWORD:Integer = $1; //计算关键词附加标识
const HL_CAL_OPT_FINGER: Integer = $2; //计算文章语义指纹标识
const HL_CAL_OPT_POS: Integer = $4; //计算词性标识
const HL_CAL_OPT_SEARCH: Integer = $8;//输出面向检索的分词结果
const NATURE_D_A:Integer = $40000000; // 形容词 形语素
const NATURE_D_B:Integer = $20000000; // 区别词 区别语素
const NATURE_D_C:Integer = $10000000; // 连词 连语素
const NATURE_D_D:Integer = $08000000; // 副词 副语素
const NATURE_D_E:Integer = $04000000; // 叹词 叹语素
const NATURE_D_F:Integer = $02000000; // 方位词 方位语素
const NATURE_D_I:Integer = $01000000; // 成语
const NATURE_D_L:Integer = $00800000; // 习语
const NATURE_A_M:Integer = $00400000; // 数词 数语素
const NATURE_D_MQ:Integer = $00200000; // 数量词
const NATURE_D_N:Integer = $00100000; // 名词 名语素
const NATURE_D_O:Integer = $00080000; // 拟声词
const NATURE_D_P:Integer = $00040000; // 介词
const NATURE_A_Q:Integer = $00020000; // 量词 量语素
const NATURE_D_R:Integer = $00010000; // 代词 代语素
const NATURE_D_S:Integer = $00008000; // 处所词
const NATURE_D_T:Integer = $00004000; // 时间词
const NATURE_D_U:Integer = $00002000; // 助词 助语素
const NATURE_D_V:Integer = $00001000; // 动词 动语素
const NATURE_D_W:Integer = $00000800; // 标点符号
const NATURE_D_X:Integer = $00000400; // 非语素字
const NATURE_D_Y:Integer = $00000200; // 语气词 语气语素
const NATURE_D_Z:Integer = $00000100; // 状态词
const NATURE_A_NR:Integer = $00000080; // 人名
const NATURE_A_NS:Integer = $00000040; // 地名
const NATURE_A_NT:Integer = $00000020; // 机构团体
const NATURE_A_NX:Integer = $00000010; // 外文字符
const NATURE_A_NZ:Integer = $00000008; // 其他专名
const NATURE_D_H:Integer = $00000004; // 前接成分
const NATURE_D_K:Integer = $00000002; // 后接成分
implementation
{$R *.dfm}
function AddNatureString(strWord:string; dwPos:longint):string;
begin
if((dwPos and NATURE_D_A) = NATURE_D_A) then
strWord := strWord +('/a')//形容词
else if((dwPos and NATURE_D_B) = NATURE_D_B) then
strWord := strWord +('/b')//区别词
else if((dwPos and NATURE_D_C) = NATURE_D_C) then
strWord := strWord +('/c')//连词
else if((dwPos and NATURE_D_D) = NATURE_D_D) then
strWord := strWord +('/d')//副词
else if((dwPos and NATURE_D_E) = NATURE_D_E) then
strWord := strWord +('/e')//叹词
else if((dwPos and NATURE_D_F) = NATURE_D_F) then
strWord := strWord +('/f')//方位词
else if((dwPos and NATURE_D_I) = NATURE_D_I) then
strWord := strWord +('/i')//成语
else if((dwPos and NATURE_D_L) = NATURE_D_L) then
strWord := strWord +('/l')//习语
else if((dwPos and NATURE_A_M) = NATURE_A_M) then
strWord := strWord +('/m')//数词
else if((dwPos and NATURE_D_MQ) = NATURE_D_MQ) then
strWord := strWord +('/mq')//数量词
else if((dwPos and NATURE_D_N) = NATURE_D_N) then
strWord := strWord + ('/n')//名词
else if((dwPos and NATURE_D_O) = NATURE_D_O) then
strWord := strWord +('/o')//拟声词
else if((dwPos and NATURE_D_P) = NATURE_D_P) then
strWord := strWord +('/p')//介词
else if((dwPos and NATURE_A_Q) = NATURE_A_Q) then
strWord := strWord +('/q')//量词
else if((dwPos and NATURE_D_R) = NATURE_D_R) then
strWord := strWord +('/r')//代词
else if((dwPos and NATURE_D_S) = NATURE_D_S) then
strWord := strWord +('/s')//处所词
else if((dwPos and NATURE_D_T) = NATURE_D_T) then
strWord := strWord +('/t')//时间词
else if((dwPos and NATURE_D_U) = NATURE_D_U) then
strWord := strWord +('/u')//助词
else if((dwPos and NATURE_D_V) = NATURE_D_V) then
strWord := strWord +('/v')//动词
else if((dwPos and NATURE_D_W) = NATURE_D_W) then
strWord := strWord +('/w')//标点符号
else if((dwPos and NATURE_D_X) = NATURE_D_X) then
strWord := strWord +('/x')//非语素字
else if((dwPos and NATURE_D_Y) = NATURE_D_Y) then
strWord := strWord +('/y')//语气词
else if((dwPos and NATURE_D_Z) = NATURE_D_Z) then
strWord := strWord +('/z')//状态词
else if((dwPos and NATURE_A_NR) = NATURE_A_NR) then
strWord := strWord +('/nr')//人名
else if((dwPos and NATURE_A_NS) = NATURE_A_NS) then
strWord := strWord +('/ns')//地名
else if((dwPos and NATURE_A_NT) = NATURE_A_NT) then
strWord := strWord +('/nt')//机构团体
else if((dwPos and NATURE_A_NX) = NATURE_A_NX) then
strWord := strWord +('/nx')//外文字符
else if((dwPos and NATURE_A_NZ) = NATURE_A_NZ) then
strWord := strWord +('/nz')//其他专名
else if((dwPos and NATURE_D_H) = NATURE_D_H) then
strWord := strWord +('/h')//前接成分
else if((dwPos and NATURE_D_K) = NATURE_D_K) then
strWord := strWord +('/k')//后接成分
else
strWord := strWord +('/?');//未知词性
Result:=strWord;
end;
procedure TForm1.Button1Click(Sender: TObject); //stdcall;
var
bSuccess:bool;
b:LPCSTR;
hHandle,DllHandle:tHANDLE;
i,iExtraCalcFlag,nResultCnt:integer;
strResult,strWord:string ;
pWord:^SHLSegWord ;
HLSplitInit:THLSplitInit;
HLFreeSplit:THLFreeSplit;
HLOpenSplit:THLOpenSplit;
HLCloseSplit:THLCloseSplit;
HLSplitWord:THLSplitWord;
HLGetWordCnt:THLGetWordCnt;
HLGetWordAt:THLGetWordAt;
begin
DllHandle:=LoadLibrary(PAnsiChar('HLSSplit.dll'));
if DllHandle=0 then
begin
ShowMessage('Loading DLL Error!');
exit;
end;
@HLSplitInit:=GetProcAddress(DllHandle,'HLSplitInit');
@HLFreeSplit:=GetProcAddress(DllHandle,'HLFreeSplit');
@HLOpenSplit:=GetProcAddress(DllHandle,'HLOpenSplit');
@HLCloseSplit:=GetProcAddress(DllHandle,'HLCloseSplit');
@HLSplitWord:=GetProcAddress(DllHandle,'HLSplitWord');
@HLGetWordCnt:=GetProcAddress(DllHandle,'HLGetWordCnt');
@HLGetWordAt:=GetProcAddress(DllHandle,'HLGetWordAt');
if (Not Assigned(@HLSplitInit)) or
(Not Assigned(@HLOpenSplit)) or
(Not Assigned(@HLCloseSplit)) or
(Not Assigned(@HLSplitWord)) or
(Not Assigned(@HLGetWordCnt)) or
(Not Assigned(@HLGetWordAt))
then
begin
showmessage('Loading function Error!');
exit;
end;
//这里说的是词库文件的路径,空表示当前路径
if(not HLSplitInit('')) then
begin
ShowMessage('海量分词初始化失败!');
Exit;
end;
//创建分词句柄
hHandle:= HLOpenSplit ();
if(hHandle = INVALID_HANDLE_VALUE) then
begin
//创建分词句柄失败
ShowMessage('创建分词句柄失败!') ;
HLFreeSplit () ;//卸载分词字典
exit;
end ;
//分词并对分词结果进行处理
iExtraCalcFlag:=HL_CAL_OPT_POS; //附加计算标志,词性计算
b:=pchar(Memo1.Text);
bSuccess:= HLSplitWord (hHandle, b, iExtraCalcFlag);
strResult:= ' ' ;
if(bSuccess) then
//分词成功
begin
nResultCnt := HLGetWordCnt (hHandle);//取得分词个数
Label1.Caption:=inttostr(nResultCnt);
for i:=0 to nResultCnt-1 do
//取得分词结果
begin
pWord:= HLGetWordAt(hHandle , i);//取得一个分词结果
if pWord.s_szWord<>'' then
begin
strWord:=(pWord.s_szWord); //PChar(pWord.s_szWord);
if(iExtraCalcFlag=HL_CAL_OPT_POS) then//词性
strWord :=AddNatureString(strWord,pWord.s_dwPOS); //显示词性标准
strResult := strResult+strWord;
strResult :=strResult+ (' ') ; //以空格分割分词结果中的每个词
end
end
end
else
//分词失败
begin
ShowMessage('分词失败!') ;
end;
//卸载分词词典
//关闭分词句柄
HLCloseSplit(hHandle);
//卸载海量分词
HLFreeSplit();
Memo2.Text:=strResult;
FreeLibrary(DllHandle);
end;
end.
在编译UEFI 程序时,可能会遇到下面的提示信息,同时如果打开了 warning as error,编译过程就会停止下来。
Warning 1 warning C4996: ‘xxxx’: This function or variable may be unsafe. Consider using fopen_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
产生这个问题的原因是一些老的库函数中包含了不安全的函数,比如可能被溢出攻击的函数。解决方法是将这个函数替换成更安全的函数,替换函数大多数是在函数名后面加入一个”_s” (这段我没有验证过)。更简单的方法是在出现问题的文件开头加入下面的代码来关闭提示让编译进行下去
#pragma warning(disable:4996)
参考:
1.http://www.rosoo.net/a/200803/6911.html
2.http://blog.csdn.net/xuleilx/article/details/7281499
公司有要求,上班的时候笔记本必须锁死在 dock 上,然后不在的时候必须拔掉钥匙锁住,每天中午都会有专人检查。于是,用Arduino做了一个简单的报警装置。
用起来是这样的:

元件上除了 Arduino 本身,还用了2个霍尔效应管(霍尔开关)作为传感器

还有一个无源蜂鸣器作为报警装置

原理上来说,在笔记本底部安装一块磁铁,在钥匙上安装一块磁铁,同时将霍尔效应管放置在与之相对的位置。当笔记本底部的霍尔效应管感受到磁力,并且钥匙处也感受到磁力,就表明笔记本放在了dock上,并且钥匙没有拔掉,此时即发出报警声音。

后来始料未及的是后来才知道,Lenovo 的笔记本dock在未锁定的状况下可以拔掉钥匙,就是说对于Lenovo的用户来说可能出现笔记本表面上看起来放置好了钥匙也拔掉了但是实际上没有锁住,而这样的情况是无法检测出来的。HP的笔记本没有这样的问题。但是鉴于上面的情况不能完全囊括,我的这个设计也就没有了多少意义。
代码如下
int KeyPin = 3; //钥匙处的霍尔开关管脚
int ButtomPin = 4; //底部的霍尔开关管脚
int BeepPin = 12; //蜂鸣器管脚
int LedPin = 13; //13Pin 上有个LED
void setup() {
pinMode(KeyPin, INPUT); //霍尔开关做输入
pinMode(ButtomPin, INPUT);//霍尔开关做输入
pinMode(BeepPin, OUTPUT); //蜂鸣器是输出
pinMode(LedPin, OUTPUT);
}
void loop() {
int i;
digitalWrite(LedPin,HIGH);
if (LOW == digitalRead(ButtomPin)) { //放回
if (LOW == digitalRead(KeyPin))
{
for(i=0;i<200;i++) //蜂鸣器响声持续时间 { digitalWrite(BeepPin,HIGH); //产生1KHz的脉冲 delayMicroseconds(500); digitalWrite(BeepPin,LOW); delayMicroseconds(500); } digitalWrite(BeepPin,LOW); delay(1000); } } digitalWrite(BeepPin,LOW); //delay(1000); digitalWrite(LedPin,LOW); }
我是在淘宝上买的Arduino UNO兼容版,同时还购买了 Arduino SENSOR SHIELD v4.0 (又叫做扩展卡,多媒体卡?)主要是为了方便实验。不过不知道该卡的扩展脚的连接,询问卖家,他随手给了Arduino的官网,但是实际上官网上并没有这个Shield的电路图。好在google可以找到

上述资料来自 http://arduino-info.wikispaces.com/SensorShield
正好搭配我购买的双母头杜邦线(不知道真的假的)。
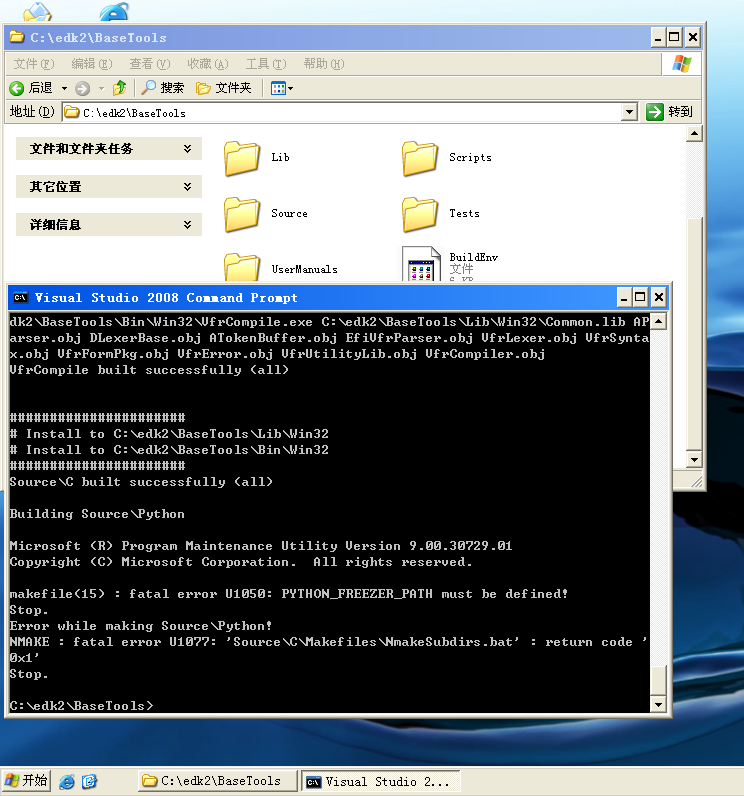
EDK2 在编译过程中会用到很多工具,比如编译处理Setup菜单的 VfrConmpiler.exe。部分工具是C编写的,部分是Python编写的。本文介绍如何重新编译Windows下面,C编写的这类工具。全部的工具存放在 BaseTools 目录下。Windows编译过程中用到的工具可以在 BaseTools\Bin\Win32下面找到。(实际上我只在Windows下编译过 EDK2)
编译的方法是:
1. 运行EDK2代码根目录下的 edksetup.bat
2. 进入BaseTools目录下运行 toolsetup.bat
3. 运行NMake即可全部重新编译
运行结果如下图,出现Error的原因是我们没有安装Python Freeze 这个工具(这个工具是用来将Python编写的程序封装成Windows EXE的工具)。
全部编译时间上会比较长,我们可以单独编译。比如,我们修改 VolInfo 的Source Code,之后进入 \basetools\Source\c\Volinfo 目录下,使用 nmake 即可编译 (前面提到的1 2两步还是要做的)
www.lab-z.com
Zoologist
2013-8-2